Visualización de Datos Geo-localizados con Python Folium, sobre Open Street Maps. Puedes consultar el código empleado en GitHub
Este fue el último Webinar del año de Women Who Code Medellín. Para 2019 planeamos volver a los Meetup presenciales en Medellín y realizar algunas actividades en Bogotá. Estén atentas a los eventos en Meetup, pueden seguirnos en Facebook e Instagram.
Como usar la librería Scikit-Learn para entrenamiento de modelos y prueba de los mismos. Código basado en Python Data Science Handbook con algunas correcciones.
Código disponible en el repositorio de GitHub de WWCode Medellín.
Los conjuntos de datos que podemos obtener no siempre cuentan con el formato o completitud necesarios para ser analizados apropiadamente. El proceso de limpieza consiste en eliminar o reemplazar elementos de un conjunto de datos de forma que afecten lo menos posible los resultados finales. Usaremos la librería Pandas de Python para realizar el proceso de limpieza de datos.
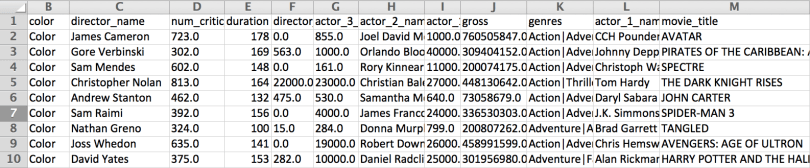
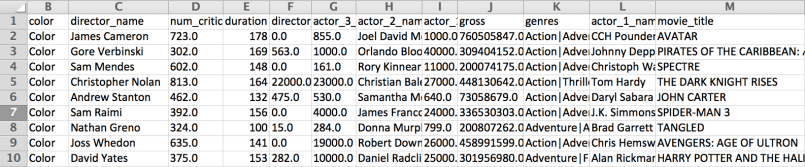
Tomaremos como referencia el código presentado en Developer Intelligence, dado que el dataset que proponen no está disponible, hemos ubicado uno similar en Kaggle, para descargarlo se debe crear una cuenta usando google o facebook. El dataset se llama iMDB 5000 Movie Dataset y contiene información sobre películas, sus rankings, fecha de estreno, título, país, entre otros datos que completan 28 columnas, en un archivo llamado “movie_metadata.csv”.
Podemos observar inspeccionando el archivo descargado que algunas filas tienen valores faltantes, tanto numéricos como texto.
Desde Python3 primero importaremos la librería pandas que ya debe estar instalada, y luego los datos indicando que la columna title_year que contiene el año de estreno sea tipo string.
>>>import pandas as pd
>>>data = pd.read_csv("movie_metadata.csv", dtype={"title_year": str})
Si desplegamos la columna title_year encontraremos que efectivamente se trata como un string sin punto decimal al final y en los campos donde no hay valores aparece NaN
>>>data["title_year"]
Podemos eliminar las filas que no tengan valor asignado en la columna title_year del siguiente modo
>>>data = data.dropna(subset=["title_year"])
Después de esta operación vemos como las filas se reducen de 5043 a 4935. Sin embargo tengamos en cuenta que en la nueva matriz los índices no se renumeran, simplemente quedan suprimidos los índices de las filas eliminadas.
Si quisiéramos eliminar todas las filas a las cuales les faltase un valor usaríamos data.dropna() para eliminar solo las filas con todos los valores faltantes usaríamos data.dropna(how=’all’) y para eliminar las filas que superen un número de valores faltantes (por ejemplo dos o más) usaríamos data.dropna(thresh=2)
Para el caso de la duración podríamos sacar estadísticas de dicha columna numérica, para ello usamos el siguiente comando.
>>>data.duration.describe()
count 4923.000000
mean 108.167378
std 22.541217
min 7.000000
25% 94.000000
50% 104.000000
75% 118.000000
max 330.000000
Name: duration, dtype: float64
Estos resultados incluyen las filas que son cero que desvían los resultados, un modo de limpiar los datos es reemplazarlas por el valor promedio de las filas restantes (sin ceros) así:
Hagamos una anotación, dado que primero se suprimieron las filas con el año de estreno vacío y luego se calculó el promedio de duración, el valor de promedio podría verse alterado por los datos suprimidos, en el video al final de este post podrás ver que al hacerlo en orden inverso hay una ligera variación del promedio.
Podemos observar los tipos de datos de todas las columnas así:
Podríamos hacer lo opuesto, convertir un valor numérico en texto, lo cual se logra del siguiente modo, lo haremos sobre un nuevo dataframe porque para nuestros datos no requerimos esa transformación.
En algunos casos es mejor reemplazar el indicador de dato faltante NaN por un texto vacío o con un texto más indicativo como “Not Known”, por ejemplo en la columna content_rating.
>>>data.content_rating= data.content_rating.fillna("Not Known")
>>> data.content_rating[96:100]
97 PG-13
98 Not Known
99 PG-13
100 PG-13
Name: content_rating, dtype: object
Podemos renombrar columnas para que tengan nombres más intuitivos
A partir de esto podremos acceder a las columnas con sus nuevos nombres
Para cambiar a mayúsculas una columna y eliminar los espacios al final usamos str.upper() y str.strip() respectivamente.
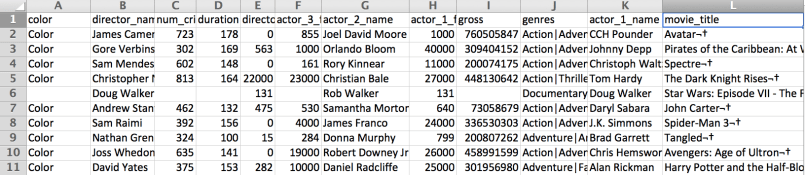
>>> data.movie_title = data["movie_title"].str.upper()
>>> data.movie_title = data["movie_title"].str.strip()
>>> data.movie_title[:10]
0 AVATAR
1 PIRATES OF THE CARIBBEAN: AT WORLD'S END
2 SPECTRE
3 THE DARK KNIGHT RISES
5 JOHN CARTER
6 SPIDER-MAN 3
7 TANGLED
8 AVENGERS: AGE OF ULTRON
9 HARRY POTTER AND THE HALF-BLOOD PRINCE
10 BATMAN V SUPERMAN: DAWN OF JUSTICE
Una vez terminamos exportamos el resultado a un nuevo archivo .csv pudiendo especificar el tipo de codificación, para el caso UTF-8
data.to_csv("cleanfile.csv", encoding="utf-8")
El resultado final nos da un archivo con el formato deseado y sin faltantes en las columnas de interés.
Si tenemos que realizar el mismo proceso con muchos archivos generaremos un script con el proceso de transformación ya probado, de modo que podamos ejecutarlo cuantas veces lo necesitemos.
El siguiente video explica de forma detallada el proceso antes descrito.
Explicamos como acceder a los tweets públicos de un usuario por medio de Python, para almacenarlos en un archivo .csv que posteriormente pueda ser cargado en un DataFrame.
Se requiere instalar la librería tweepy (El manejador de paquetes pip ya debe estar instalado, para instalar pip puedes consultar como Aquí)
pip3 install tweepy
Obtener tokens de acceso para conectarse a Twitter
Llenar los campos mandatorios de nombre, descripción y sitio web. Este último puede no ser una página activa dado que nuestra conexión será de solo lectura
Aceptar los términos y condiciones y dar click en “Crear twitter app”
Una vez creada la aplicación ir a la pestaña de “Permisos” y cambiarlos por “Solo lectura”, esto es importante pues solo la usaremos para descarga de datos, no para publicar nada en tu cuenta.
Recibirás una alerta de que debes esperar a que los permisos se actualicen, una vez actualizados ve a la pestaña “Tokens de acceso”
Dar click sobre “Crear Tokens de acceso” para generar las credenciales que la aplicación usará. Estos datos son privados, cualquiera que los tenga podrá conectarse a twitter a nombre de tu aplicación.
Usa el código a continuación y guárdalo en un archivo de script Python tweets.py
import tweepy #https://github.com/tweepy/tweepy
import csv
#Credenciales del Twitter API
consumer_key = "Agregar Consumer Key"
consumer_secret = "Agregar Consumer Secret"
access_key = "Agregar Access Key"
access_secret = "Agregar Access Secret"
#Remover los caracteres no imprimibles y los saltos de línea del texto del tweet
def strip_undesired_chars(tweet):
stripped_tweet = tweet.replace('\n', ' ').replace('\r', '')
char_list = [stripped_tweet[j] for j in range(len(stripped_tweet)) if ord(stripped_tweet[j]) in range(65536)]
stripped_tweet=''
for j in char_list:
stripped_tweet=stripped_tweet+j
return stripped_tweet
def get_all_tweets(screen_name):
#Este método solo tiene permitido descargar máximo los ultimos 3240 tweets del usuario
#Especificar aquí durante las pruebas un número entre 200 y 3240
limit_number = 3240
#autorizar twitter, inicializar tweepy
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_key, access_secret)
api = tweepy.API(auth)
#inicializar una list to para almacenar los Tweets descargados por tweepy
alltweets = []
#Hacer una petición inicial por los 200 tweets más recientes (200 es el número máximo permitido)
new_tweets = api.user_timeline(screen_name = screen_name,count=200)
#guardar los tweets más recientes
alltweets.extend(new_tweets)
#guardar el ID del tweet más antiguo menos 1
oldest = alltweets[-1].id - 1
#recorrer todos los tweets en la cola hasta que no queden más
while len(new_tweets) > 0 and len(alltweets) <= limit_number:
print ("getting tweets before" + str(oldest))
#en todas las peticiones siguientes usar el parámetro max_id para evitar duplicados
new_tweets = api.user_timeline(screen_name = screen_name,count=200,max_id=oldest)
#guardar los tweets descargados
alltweets.extend(new_tweets)
#actualizar el ID del tweet más antiguo menos 1
oldest = alltweets[-1].id - 1
#informar en la consola como vamos
print (str(len(alltweets)) + " tweets descargados hasta el momento")
#transformar los tweets descargados con tweepy en un arreglo 2D array que llenará el csv
outtweets = [(tweet.id_str, tweet.created_at, strip_undesired_chars(tweet.text),tweet.retweet_count,str(tweet.favorite_count)+'') for tweet in alltweets]
#escribir el csv
with open('%s_tweets.csv' % screen_name, "w", newline='') as f:
writer = csv.writer(f, quoting=csv.QUOTE_ALL)
writer.writerow(['id','created_at','text','retweet_count','favorite_count'''])
writer.writerows(outtweets)
pass
if __name__ == '__main__':
#especificar el nombre de usuario de la cuenta a la cual se descargarán los tweets
get_all_tweets("Agregar TwitterUser")
Ejecutar el script según se indica a continuación, esto creará un archivo llamado TwitterUser_tweets.csv
python3 tweets.py
Fuente original del código Aquí, se hicieron cambios para compatibilidad con Python 3, para garantizar que todas las columnas quedan entre “”, eliminar los saltos de línea de los tweets y los emoticones que pueden generar problemas al leer el archivo .csv resultante desde python.
Para cargar el archivo .csv en un Dataframe de Python
Continuamos con la temática de Ciencia de Datos para los Meetups de Women Who Code Medellín, este mes tratamos generación de datos aleatorios usando la librería Numpy de Python.
Reglas del juego que se presenta como ejemplo para ser resuelto simulando datos aleatorios para resolver la pregunta ¿Cuál es la probabilidad de Ganar este juego?
REGLAS
Se usa un dado para jugar, por lo cual los valores son de 1 a 6
Si tiramos 3 o menos devolvemos 1 peso al juego
Si tiramos más de 3 y hasta 5 nos dan 1 peso
Si tiramos 6, entonces tiramos de nuevo el dado y nos dan tantos pesos como el dado lo indique.
Jugamos con monedas, de modo que no hay valores de pesos negativos
El turno del jugador consiste en tirar el dado 100 veces
Se gana el juego si se obtiene más de 50 pesos al final del turno
Aquí el código que usamos en la presentación.
import numpy as np
import matplotlib.pyplot as plt
#Iniciar la semilla para garantizar que los datos serán iguales cada que se corra el algoritmo
np.random.seed(204)
todos_turnos = []
#Definir cuántas veces se corre la simulación
muestras = 600
for x in range(muestras) :
#Comenzar el turno sin monedas
monedas = 0
turno_aleatorio = [0]
for x in range(100) :
dado = np.random.randint(1,7)
if dado <= 3 :
monedas = max(0,monedas - 1)
elif dado < 6 :
monedas = monedas + 1
else :
monedas = monedas + np.random.randint(1,7)
#Registrar cuantas monedas tengo al final de cada tirada
turno_aleatorio.append(monedas)
#Guardar los resultados del turno
todos_turnos.append(turno_aleatorio)
#Formatear el arreglo como numpy array
np_todos_turnos = np.array(todos_turnos)
#Trasponer filas por columnas para adaptar a la gráfica
np_todos_turnos_t = np.transpose(np_todos_turnos)
#Sacar la última fila - resultado final de todos los turnos
ultimos = np_todos_turnos_t[-1,:]
#Calcular probabilidad de ganar contando los valores del vector
#mayores o iguales a 50 y dividiendo por el número de turnos
print('La probabilidad de ganar el juego es de ' + str(round(100*(ultimos >= 50).sum()/muestras,2)) + '%')
#Preparar la Gráfica del desarrollo de todos los turnos
plt.figure(200)
plt.xlabel('Cantidad lanzamientos del dado')
plt.ylabel('Monedas')
plt.title('Desarrollo de '+ str(muestras)+ ' turnos')
plt.plot(np_todos_turnos_t)
#Preparar la Gráfica de distribución de los turnos
plt.figure(300)
plt.xlabel('Total de monedas al final del turno')
plt.ylabel('Cantidad de turnos en el rango del total')
plt.title('Histograma para '+ str(muestras)+ ' turnos')
plt.hist(ultimos)
#Mostrar las gráficas
plt.show()
Les compartimos el hangout de Women Who Code Medellín de Abril, donde hablamos de carga de datos externos usando la librería Python de Pandas y realizando gráficos con ellos.
Con más detalle sobre graficación puedes ver el meetup de marzo.
Estamos en proceso de hacer meetups presenciales en la ciudad de Bogotá, les estaremos avisando.
El instalador se ejecuta, para el caso de OSX por tratarse de un paquete no firmado mostrará un error, luego se debe ingresarse a Preferencias del Sistema -> Seguridad y privacidad. En la opción: “Permitir apps descargadas de” verá una advertencia por el paquete recién ejecutado, se autoriza que se ejecute y se procede a instalar.
OSX tiene una versión preinstalada (2.7), la versión que se descarga quedará instalada solo para el usuario y no afecta la versión del sistema operativo.
Para instalar el manejador de paquetes pip, se descarga el script get-pip.py desde una fuente confiable como https://bootstrap.pypa.io/get-pip.py una vez descargado se ejecuta:
python3 get-pip.py
Esto instalará las dependencias necesarias, tenga en cuenta que python3 se refiere a la versión instalada, si usa python solamente en el comando intentará hacerlo sobre la versión del sistema operativo y generará errores de permisos.
Una vez instalado pip para instalar nuevos paquetes en python, por ejemplo Numpy, usar el manejador de paquetes de este modo para instalar el paquete básico de computación científica en Python:
pip3 install numpy
Notar nuevamente el uso del comando como pip3 para que el sistema operativo ubique apropiadamente la versión con la cual se trabaja.
Seleccione el entorno de desarrollo de su preferencia, uno IDE sencillo para principiantes puede ser Thony, el cual puede descargarse de http://thonny.org
Para el trabajo con gráficas es importante instalar un paquete que pueda trazarlas.
pip3 install matplotlib
Otras librerías útiles para instalar:
Trabajo avanzado con fechas: dateutil
Uso de tablas de datos e importarlos desde csv: pandas
pip3 install python-dateutil
pip3 install pandas
Más sobre operaciones básicas con Python y uso de Numpy AQUÍ