Por: Isabel Yepes
 ¿Alguna vez has tenido un accidente con tu teléfono? ¿Algo así como sumergirlo en agua y que no vuelva a funcionar la pantalla? ¿Has dejado caer tu portátil al piso y como resultado ha dejado de encender? Después de estos sucesos lo peor que puede ocurrirnos es quedarnos sin acceso a nuestros datos y perderlos ¿Cuáles datos? Las cosas que nos importan, las fotos del último cumpleaños, la lista de contactos de personas allegadas cuyos números telefónicos ya no memorizamos, la preciada última copia de la tesis que llevamos meses desarrollando.
¿Alguna vez has tenido un accidente con tu teléfono? ¿Algo así como sumergirlo en agua y que no vuelva a funcionar la pantalla? ¿Has dejado caer tu portátil al piso y como resultado ha dejado de encender? Después de estos sucesos lo peor que puede ocurrirnos es quedarnos sin acceso a nuestros datos y perderlos ¿Cuáles datos? Las cosas que nos importan, las fotos del último cumpleaños, la lista de contactos de personas allegadas cuyos números telefónicos ya no memorizamos, la preciada última copia de la tesis que llevamos meses desarrollando.
El punto débil de este tipo de información es que normalmente la ubicamos en un solo dispositivo, nuestra estrategia de tener todos los huevos en la misma canasta es riesgosa, pero solo pensamos en que como personas particulares podemos perder algo en el momento que realmente nos sucede y ya no tenemos forma de recuperarlo.
La palabra backup o respaldo debería ser más popular entre las personas, porque finalmente un daño de información causa algún tipo de pérdida, así sea solo ese video perfecto que le sacaste al gato el año pasado, tiene un valor que puede no ser económico sino relativo a la importancia que ese elemento intangible representa para su poseedor.
¿Y cómo podemos proteger nuestros datos personales? La forma más sencilla es hacer una copia localizada en un sitio físicamente diferente, usar USBs o discos externos puede ser una alternativa para el caso de los equipos de cómputo pero requiere disciplina de realizar manualmente el proceso de copia. En el caso de los teléfonos celulares y tablets no todos admiten la conexión de unidades externas de almacenamiento y esto puede complicar las cosas especialmente para personas sin mucho conocimiento en informática.
Allí aparece la nube como una alternativa sencilla para realizar respaldos de datos, en especial por la conveniencia de ser independiente de dispositivos físicos que pueden extraviarse también y porque es posible configurar el proceso de copia hacia la nube para que se realice de forma automática, si, así sin que nos demos cuenta los datos se están guardando ellos mismos y están disponibles cuando los necesitemos.
 Tal vez el asunto de la nube parezca a las personas comunes y corrientes algo un poco etéreo ¿Dónde está la nube? ¿Quién es el dueño de la nube? ¿Cómo llegan los datos hasta allí? ¿Cómo se garantiza que efectivamente pueda recuperar mis fotos, videos, contactos? ¿Alguien que no sea yo puede leer eso? Es importante hacerse esas preguntas, especialmente en términos de privacidad es conveniente saber qué políticas aplican al lugar de almacenamiento de mis datos, si están siendo alojados en otro país o en el mío, si existe un consumo de mi plan de datos (para el caso de los celulares) en el proceso de respaldo.
Tal vez el asunto de la nube parezca a las personas comunes y corrientes algo un poco etéreo ¿Dónde está la nube? ¿Quién es el dueño de la nube? ¿Cómo llegan los datos hasta allí? ¿Cómo se garantiza que efectivamente pueda recuperar mis fotos, videos, contactos? ¿Alguien que no sea yo puede leer eso? Es importante hacerse esas preguntas, especialmente en términos de privacidad es conveniente saber qué políticas aplican al lugar de almacenamiento de mis datos, si están siendo alojados en otro país o en el mío, si existe un consumo de mi plan de datos (para el caso de los celulares) en el proceso de respaldo.
Existen muchas soluciones gratuitas y de pago para realizar copias de respaldo en la nube, los fabricantes de teléfonos pueden permitir sincronizar alguna información como contactos sin costo, como conectar la cuenta de Gmail al teléfono Android o configurar iCloud en un iPhone, pero normalmente el almacenamiento de archivos, fotos y video requiere una suscripción paga pues dichos elementos ocupan espacio en la nube, que en últimas está compuesta por computadores tipo servidor y que para mantenerse encendidos y disponibles para nosotros requieren entre otras energía eléctrica, refrigeración de aire acondicionado, personas que los administren, en últimas el pago que hacemos es una fracción muy pequeña del costo, porque al ser la nube usada por muchas personas a la vez podemos pagarlo entre todos ¿Colaborativo verdad?
Un ejemplo de un servicio de respaldo de datos pago para personas es Movistar Cloud, es un repositorio en la nube que permite almacenar fotos, videos, archivos de música, entre otros y darle ciertas funcionalidades adicionales como compartir los archivos con personas específicas, sincronizar los contactos, configurar respaldo automático del dispositivo. Este servicio está de hecho incluido para quienes tengan planes telefónicos en Colombia con minutos ilimitados y algunas personas no lo saben y se quedan sin sacar provecho de ello.
La recomendación final, indaga si tu teléfono cuenta con algún sistema de respaldo automático que puedas configurar, infórmate si hay opciones gratuitas, si hay opciones de pago que ya vengan incluidas en lo que tienes, si puede extenderse a otros dispositivos distintos al teléfono (algunos software de antivirus pagos ofrecen almacenamiento de respaldo en la nube para el PC y la gente lo ignora), y si tienes muchos archivos examina opciones pagas que se ajusten a tu presupuesto y al valor que le das a tu información. Mantente enterado de las condiciones de uso y privacidad de los datos que cargas en la nube.
También recuerda depurar tus archivos, almacena aquello que consideras realmente valioso y borra lo que ya no necesitas, esto ayuda en términos de economía y es sensible con el planeta, la nube es un lugar físico que consume recursos de energía y agua, como usuarios individuales también es positivo ser conscientes de ello.













 Las MiPyMEs en Colombia dan cuenta del 35% del PIB, el 80% del empleo y 90% del sector productivo nacional según datos del DANE (1), pensando en estos términos los factores que ayuden a mejorar la competitividad de estas empresas son relevantes para el movimiento de la economía y la prosperidad económica del país. En un mundo globalizado como el que vivimos la vitrina virtual del Internet le permite a estas empresas acceder a clientes en cualquier lugar del mundo y a la vez tener competidores ubicados en cualquier país del globo.
Las MiPyMEs en Colombia dan cuenta del 35% del PIB, el 80% del empleo y 90% del sector productivo nacional según datos del DANE (1), pensando en estos términos los factores que ayuden a mejorar la competitividad de estas empresas son relevantes para el movimiento de la economía y la prosperidad económica del país. En un mundo globalizado como el que vivimos la vitrina virtual del Internet le permite a estas empresas acceder a clientes en cualquier lugar del mundo y a la vez tener competidores ubicados en cualquier país del globo.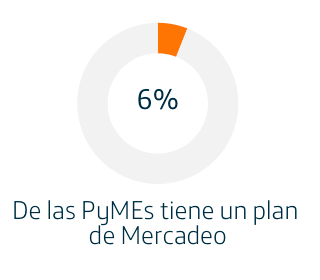 La estructura de las PyMEs implica que no cuentan con departamentos especializados para asuntos como el mercadeo o la tecnología, solo un 6% de ellas cuentan con un plan de Mercadeo, en cuanto al uso de tecnologías digitales de marketing el 98% de las empresas dice no contar con personal capacitado en la gestión de un plan de Marketing digital, encontrándose que en la mayoría es gestionado por el gerente-propietario de la empresa y quien normalmente actúa según se lo permitan las necesidades del día a día que están enfocadas en la respuesta a los clientes actuales.
La estructura de las PyMEs implica que no cuentan con departamentos especializados para asuntos como el mercadeo o la tecnología, solo un 6% de ellas cuentan con un plan de Mercadeo, en cuanto al uso de tecnologías digitales de marketing el 98% de las empresas dice no contar con personal capacitado en la gestión de un plan de Marketing digital, encontrándose que en la mayoría es gestionado por el gerente-propietario de la empresa y quien normalmente actúa según se lo permitan las necesidades del día a día que están enfocadas en la respuesta a los clientes actuales.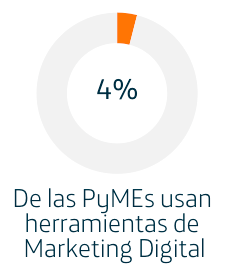 Si bien el Internet facilita la comunicación con clientes y proveedores, el uso sistemático de este como herramienta de Marketing no está todavía extendido en el segmento de las PyMEs, solo el 4% de las empresas usan explícitamente Marketing Digital como parte de su estrategia de negocio. Al mismo tiempo la cantidad de PyMEs que lo utiliza de forma completa integrando SEO (Search Engine Optimization), SMO (Social Media Optimization), SEA (Search Engine Advertising) y Analytics: Stats + Metrics es es muchísimo menor, del orden del 1%. (2)
Si bien el Internet facilita la comunicación con clientes y proveedores, el uso sistemático de este como herramienta de Marketing no está todavía extendido en el segmento de las PyMEs, solo el 4% de las empresas usan explícitamente Marketing Digital como parte de su estrategia de negocio. Al mismo tiempo la cantidad de PyMEs que lo utiliza de forma completa integrando SEO (Search Engine Optimization), SMO (Social Media Optimization), SEA (Search Engine Advertising) y Analytics: Stats + Metrics es es muchísimo menor, del orden del 1%. (2) Una gestión completa de la presencia digital implica más que simplemente tener una página web, que sería simplemente el primer paso, integra también la gestión de redes sociales y la generación de contenido relevante que ayude a apalancar la venta y presentación de productos y servicios. Para evitar que se convierta en complejidad innecesaria es bueno contar con constructores web y herramientas integradoras, que permitan administrar desde una única interfaz el sitio web, redes sociales, analítica de datos de visitas y comercio electrónico.
Una gestión completa de la presencia digital implica más que simplemente tener una página web, que sería simplemente el primer paso, integra también la gestión de redes sociales y la generación de contenido relevante que ayude a apalancar la venta y presentación de productos y servicios. Para evitar que se convierta en complejidad innecesaria es bueno contar con constructores web y herramientas integradoras, que permitan administrar desde una única interfaz el sitio web, redes sociales, analítica de datos de visitas y comercio electrónico.
