AWS re:Invent es el evento de Amazon donde realizan todos los lanzamientos de servicios que serán desplegados en el siguiente año. Compartimos este webinar donde hablamos de las nuevas funcionalidades y negocios que la plataforma de cloud computing más ampliamente usada en el mercado plantea.
En el último webinar del año de 0 a 100 en Cloud Computing hablamos de las ventajas del uso de Bases de Datos ubicadas en infraestructura en la nube, y nos adentramos en las Bases de datos SQL en Microsoft Azure con un demo de como configurar una base de datos SQL Server y gestión básica.
¿Sabías que el 60% de las compañías que sufren pérdidas importantes de datos tienen riesgo de cerrar en los siguientes 6 meses?* En este webinar hablamos de la importancia de los planes de recuperación y del uso de sistemas de backup en la nube. En esta ocasión exploramos Azure Backup as a service y desarrollamos un demo de backup sobre una máquina virtual completa, incluyendo restauración parcial de archivos y recuperación total de copia.
Continuando con los temas de DevOps, este webinar muestra como realizar despliegue automático de código alojado en un repositorio en GitHub, hacia una WebApp ubicada en la nube de Azure, utilizando como pipeline Azure DevOps. Una vez configurado cada commit sobre el repositorio desencadena un despliegue automático sobre la WebApp.
Como usar la librería Scikit-Learn para entrenamiento de modelos y prueba de los mismos. Código basado en Python Data Science Handbook con algunas correcciones.
Código disponible en el repositorio de GitHub de WWCode Medellín.
Compartimos el webinar realizado en el grupo de Meetup De 0 a 100 en cloud computing, donde tratamos el tema de SaaS (Software as a Service) en este caso las plataformas en la nube que permiten a las empresas hacer más eficientes las reuniones de sus equipos de trabajo y facilitar la interacción remota con empleados, proveedores y clientes. Detallamos los servicios que ofrece Microsoft bajo la sombrilla de Office 365, los cuales más allá de la ofimática brindan herramientas de redes sociales corporativas, intranet, teleconferencia, chat, seguimiento de proyectos, entre otros. Al final se realiza un demo en línea sobre la herramienta Microsoft Teams y su uso en dispositivos móviles.
Los conjuntos de datos que podemos obtener no siempre cuentan con el formato o completitud necesarios para ser analizados apropiadamente. El proceso de limpieza consiste en eliminar o reemplazar elementos de un conjunto de datos de forma que afecten lo menos posible los resultados finales. Usaremos la librería Pandas de Python para realizar el proceso de limpieza de datos.
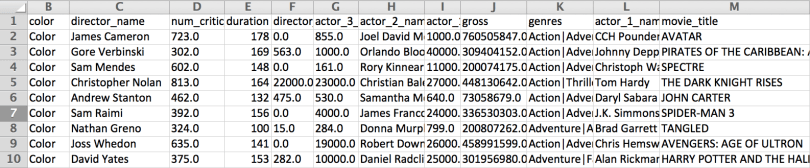
Tomaremos como referencia el código presentado en Developer Intelligence, dado que el dataset que proponen no está disponible, hemos ubicado uno similar en Kaggle, para descargarlo se debe crear una cuenta usando google o facebook. El dataset se llama iMDB 5000 Movie Dataset y contiene información sobre películas, sus rankings, fecha de estreno, título, país, entre otros datos que completan 28 columnas, en un archivo llamado “movie_metadata.csv”.
Podemos observar inspeccionando el archivo descargado que algunas filas tienen valores faltantes, tanto numéricos como texto.
Desde Python3 primero importaremos la librería pandas que ya debe estar instalada, y luego los datos indicando que la columna title_year que contiene el año de estreno sea tipo string.
>>>import pandas as pd
>>>data = pd.read_csv("movie_metadata.csv", dtype={"title_year": str})
Si desplegamos la columna title_year encontraremos que efectivamente se trata como un string sin punto decimal al final y en los campos donde no hay valores aparece NaN
>>>data["title_year"]
Podemos eliminar las filas que no tengan valor asignado en la columna title_year del siguiente modo
>>>data = data.dropna(subset=["title_year"])
Después de esta operación vemos como las filas se reducen de 5043 a 4935. Sin embargo tengamos en cuenta que en la nueva matriz los índices no se renumeran, simplemente quedan suprimidos los índices de las filas eliminadas.
Si quisiéramos eliminar todas las filas a las cuales les faltase un valor usaríamos data.dropna() para eliminar solo las filas con todos los valores faltantes usaríamos data.dropna(how=’all’) y para eliminar las filas que superen un número de valores faltantes (por ejemplo dos o más) usaríamos data.dropna(thresh=2)
Para el caso de la duración podríamos sacar estadísticas de dicha columna numérica, para ello usamos el siguiente comando.
>>>data.duration.describe()
count 4923.000000
mean 108.167378
std 22.541217
min 7.000000
25% 94.000000
50% 104.000000
75% 118.000000
max 330.000000
Name: duration, dtype: float64
Estos resultados incluyen las filas que son cero que desvían los resultados, un modo de limpiar los datos es reemplazarlas por el valor promedio de las filas restantes (sin ceros) así:
Hagamos una anotación, dado que primero se suprimieron las filas con el año de estreno vacío y luego se calculó el promedio de duración, el valor de promedio podría verse alterado por los datos suprimidos, en el video al final de este post podrás ver que al hacerlo en orden inverso hay una ligera variación del promedio.
Podemos observar los tipos de datos de todas las columnas así:
Podríamos hacer lo opuesto, convertir un valor numérico en texto, lo cual se logra del siguiente modo, lo haremos sobre un nuevo dataframe porque para nuestros datos no requerimos esa transformación.
En algunos casos es mejor reemplazar el indicador de dato faltante NaN por un texto vacío o con un texto más indicativo como “Not Known”, por ejemplo en la columna content_rating.
>>>data.content_rating= data.content_rating.fillna("Not Known")
>>> data.content_rating[96:100]
97 PG-13
98 Not Known
99 PG-13
100 PG-13
Name: content_rating, dtype: object
Podemos renombrar columnas para que tengan nombres más intuitivos
A partir de esto podremos acceder a las columnas con sus nuevos nombres
Para cambiar a mayúsculas una columna y eliminar los espacios al final usamos str.upper() y str.strip() respectivamente.
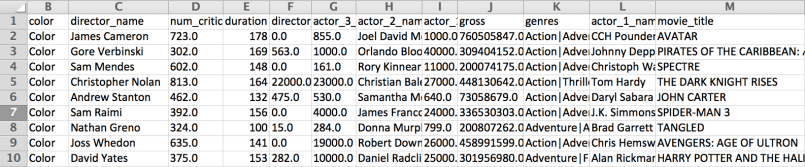
>>> data.movie_title = data["movie_title"].str.upper()
>>> data.movie_title = data["movie_title"].str.strip()
>>> data.movie_title[:10]
0 AVATAR
1 PIRATES OF THE CARIBBEAN: AT WORLD'S END
2 SPECTRE
3 THE DARK KNIGHT RISES
5 JOHN CARTER
6 SPIDER-MAN 3
7 TANGLED
8 AVENGERS: AGE OF ULTRON
9 HARRY POTTER AND THE HALF-BLOOD PRINCE
10 BATMAN V SUPERMAN: DAWN OF JUSTICE
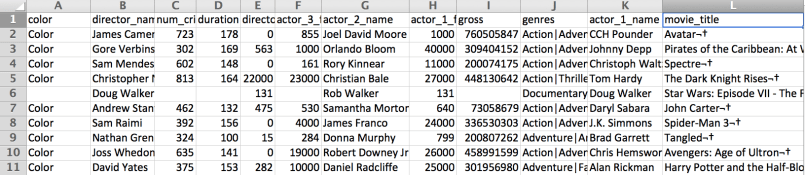
Una vez terminamos exportamos el resultado a un nuevo archivo .csv pudiendo especificar el tipo de codificación, para el caso UTF-8
data.to_csv("cleanfile.csv", encoding="utf-8")
El resultado final nos da un archivo con el formato deseado y sin faltantes en las columnas de interés.
Si tenemos que realizar el mismo proceso con muchos archivos generaremos un script con el proceso de transformación ya probado, de modo que podamos ejecutarlo cuantas veces lo necesitemos.
El siguiente video explica de forma detallada el proceso antes descrito.
Compartimos el webinar realizado en el grupo de Meetup De 0 a 100 en cloud computing, donde tratamos una introducción a los servicios de Telefónica Open Cloud, plataforma de Nube Pública basada en la tecnología OpenSource de OpenStack, con un demo básico de aprovisionamiento de un servidor en la nube con un servicio web en Centos.
En esta publicación mostramos como hacer un análisis de palabras simple denominado WordCloud, que muestra una imagen con las palabras más frecuentes en un texto, dándoles relevancia por tamaño. Usaremos como fuente textual los tweets de una determinada cuenta, que han sido previamente descargados en csv.
Una vez instalado nltk debemos descargar los diccionarios de palabras que necesitamos, para este caso las stopwords, que son las palabras conectoras que repetimos con frecuencia en un idioma, por ejemplo pronombres como el, la, los, e.o.
En el caso de OSX la descarga requiere que la fuente tenga un certificado instalado, por lo cual debemos cumplir este requisito antes de hacer la descarga, ingresando a la ruta de la aplicación e instalando el certificado
Debemos contar ya con un archivo con información de twitter descargada, puedes tomar como referencia las instrucciones de Como descargar tweets a .csv usando Python teniendo en cuenta que la forma de crear credenciales de descarga para twitter cambió y ahora debes aplicar por una cuenta de desarrollador antes de crear la aplicación. El video al final de este post habla un poco de ello. En este enlace de Twitter Developer puedes comenzar ese proceso.
El siguiente script contempla que tienes dos archivos, uno con los 400 últimos tweets llamado sample_tweets-400.csv y otro con los últimos 3240 llamado sample_tweets.csv. Este script también puede encontrarse en el siguiente repositorio, con el nombre wordcloud.py https://github.com/WomenWhoCode/WWCodeMedellin
import numpy as np
import pandas as pd
import re
#Visualización
import matplotlib.pyplot as plt
import matplotlib
from wordcloud import WordCloud, STOPWORDS
#nltk librería de análisis de lenguaje
import nltk
#Este proceso puede hacerse antes de forma manual, descargar las stopwords de la librería nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stop_words_sp = set(stopwords.words('spanish'))
stop_words_en = set(stopwords.words('english'))
#Concatenar las stopwords aplicándose a una cuenta que genera contenido en inglés y español
stop_words = stop_words_sp | stop_words_en
from nltk import tokenize
matplotlib.style.use('ggplot')
pd.options.mode.chained_assignment = None
#Últimos 400 tweets previamente descargados
tweets = pd.read_csv('sample_tweets-400.csv')
#Últimos 3240 tweets previamente descargados
tweets2 = pd.read_csv('sample_tweets.csv')
def wordcloud(tweets,col,idgraf):
#Crear la imagen con las palabras más frecuentes
wordcloud = WordCloud(background_color="white",stopwords=stop_words,random_state = 2016).generate(" ".join([i for i in tweets[col]]))
#Preparar la figura
plt.figure(num=idgraf, figsize=(20,10), facecolor='k')
plt.imshow(wordcloud)
plt.axis("off")
plt.title("Good Morning Datascience+")
def tweetprocess(tweets,idgraf):
#Monitorear que ha ingresado a procesar el gráfico
print(idgraf)
#Imprimir un tweet que sepamos contenga RT @, handles y puntuación para ver su eliminación
print(tweets['text'][3])
tweets['tweetos'] = ''
#add tweetos first part
for i in range(len(tweets['text'])):
try:
tweets['tweetos'][i] = tweets['text'].str.split(' ')[i][0]
except AttributeError:
tweets['tweetos'][i] = 'other'
#Prepocesar tweets con 'RT @'
for i in range(len(tweets['text'])):
if tweets['tweetos'].str.contains('@')[i] == False:
tweets['tweetos'][i] = 'other'
# Remover URLs, RTs, y twitter handles
for i in range(len(tweets['text'])):
tweets['text'][i] = " ".join([word for word in tweets['text'][i].split()
if 'http' not in word and '@' not in word and '<' not in word and 'RT' not in word])
#Monitorear que se removieron las menciones y URLs
print("------Después de remover menciones y URLs --------")
print(tweets['text'][3])
#Remover puntuación, se agregan símbolos del español
tweets['text'] = tweets['text'].apply(lambda x: re.sub('[¡!@#$:).;,¿?&]', '', x.lower()))
tweets['text'] = tweets['text'].apply(lambda x: re.sub(' ', ' ', x))
#Monitorear que se removió la puntuación y queda en minúsculas
print("------Después de remover signos de puntuación y pasar a minúsculas--------")
print(tweets['text'][3])
#hacer el análisis de WordCloud
wordcloud(tweets,'text',idgraf)
#Graficar tendencia 400 tweets
tweetprocess(tweets,100)
#Graficar tendencia 3240 tweets
tweetprocess(tweets2,200)
plt.show()
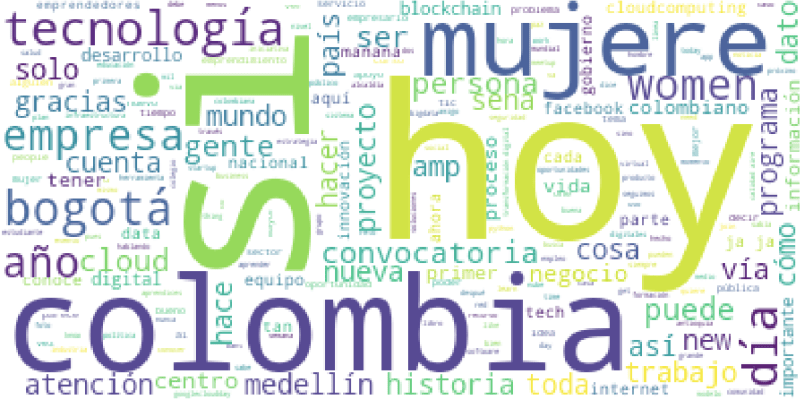
La salida generada son dos imágenes que muestran la tendencia de los últimos 400 tweets y los últimos 3240
Word Cloud para los últimos 400 tweetsWord Cloud para los últimos 3240 tweets