
Por: Isabel Yepes
Los conjuntos de datos que podemos obtener no siempre cuentan con el formato o completitud necesarios para ser analizados apropiadamente. El proceso de limpieza consiste en eliminar o reemplazar elementos de un conjunto de datos de forma que afecten lo menos posible los resultados finales. Usaremos la librería Pandas de Python para realizar el proceso de limpieza de datos.
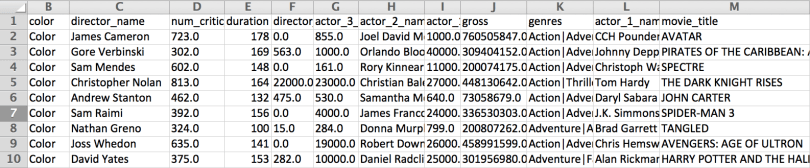
Tomaremos como referencia el código presentado en Developer Intelligence, dado que el dataset que proponen no está disponible, hemos ubicado uno similar en Kaggle, para descargarlo se debe crear una cuenta usando google o facebook. El dataset se llama iMDB 5000 Movie Dataset y contiene información sobre películas, sus rankings, fecha de estreno, título, país, entre otros datos que completan 28 columnas, en un archivo llamado “movie_metadata.csv”.
Podemos observar inspeccionando el archivo descargado que algunas filas tienen valores faltantes, tanto numéricos como texto.
Desde Python3 primero importaremos la librería pandas que ya debe estar instalada, y luego los datos indicando que la columna title_year que contiene el año de estreno sea tipo string.
>>>import pandas as pd
>>>data = pd.read_csv("movie_metadata.csv", dtype={"title_year": str})
Si desplegamos la columna title_year encontraremos que efectivamente se trata como un string sin punto decimal al final y en los campos donde no hay valores aparece NaN
>>>data["title_year"]

Podemos eliminar las filas que no tengan valor asignado en la columna title_year del siguiente modo
>>>data = data.dropna(subset=["title_year"])
Después de esta operación vemos como las filas se reducen de 5043 a 4935. Sin embargo tengamos en cuenta que en la nueva matriz los índices no se renumeran, simplemente quedan suprimidos los índices de las filas eliminadas.

Si quisiéramos eliminar todas las filas a las cuales les faltase un valor usaríamos data.dropna() para eliminar solo las filas con todos los valores faltantes usaríamos data.dropna(how=’all’) y para eliminar las filas que superen un número de valores faltantes (por ejemplo dos o más) usaríamos data.dropna(thresh=2)
Para el caso de la duración podríamos sacar estadísticas de dicha columna numérica, para ello usamos el siguiente comando.
>>>data.duration.describe() count 4923.000000 mean 108.167378 std 22.541217 min 7.000000 25% 94.000000 50% 104.000000 75% 118.000000 max 330.000000 Name: duration, dtype: float64
Estos resultados incluyen las filas que son cero que desvían los resultados, un modo de limpiar los datos es reemplazarlas por el valor promedio de las filas restantes (sin ceros) así:
>>>data.duration = data.duration.fillna(data.duration.mean())
Si buscamos en la columna los valores que antes eran cero por rangos, podremos ver lo siguiente.
>>> data.duration[190:200] 192 101.000000 193 138.000000 194 107.000000 195 142.000000 196 165.000000 197 100.000000 198 82.000000 199 108.167378 200 98.000000 201 95.000000 Name: duration, dtype: float64
Hagamos una anotación, dado que primero se suprimieron las filas con el año de estreno vacío y luego se calculó el promedio de duración, el valor de promedio podría verse alterado por los datos suprimidos, en el video al final de este post podrás ver que al hacerlo en orden inverso hay una ligera variación del promedio.
Podemos observar los tipos de datos de todas las columnas así:
>>> data.dtypes color object director_name object num_critic_for_reviews float64 duration int32 director_facebook_likes float64
Si no es relevante conservar los decimales del promedio, podemos convertir esta columna de formato flotante en entera del siguiente modo.
>>> data.duration = pd.Series(data["duration"], dtype="int32")
Al visualizar el mismo rango ya no tendrá los decimales por tratarse de valores enteros.
>>> data.duration[190:200] 192 101 193 138 194 107 195 142 196 165 197 100 198 82 199 108 200 98 201 95 Name: duration, dtype: int32
Podríamos hacer lo opuesto, convertir un valor numérico en texto, lo cual se logra del siguiente modo, lo haremos sobre un nuevo dataframe porque para nuestros datos no requerimos esa transformación.
>>>data2 = data.duration.astype(str) >>> data2[:10] 0 178 1 169 2 148 3 164 5 132 6 156 7 100 8 141 9 153 10 183 Name: duration, dtype: object
En algunos casos es mejor reemplazar el indicador de dato faltante NaN por un texto vacío o con un texto más indicativo como “Not Known”, por ejemplo en la columna content_rating.
>>>data.content_rating = data.content_rating.fillna("Not Known") >>> data.content_rating[96:100] 97 PG-13 98 Not Known 99 PG-13 100 PG-13 Name: content_rating, dtype: object
Podemos renombrar columnas para que tengan nombres más intuitivos
>>>data = data.rename(columns = {"title_year":"release_date", "movie_facebook_likes":"facebook_likes"})
A partir de esto podremos acceder a las columnas con sus nuevos nombres
Para cambiar a mayúsculas una columna y eliminar los espacios al final usamos str.upper() y str.strip() respectivamente.
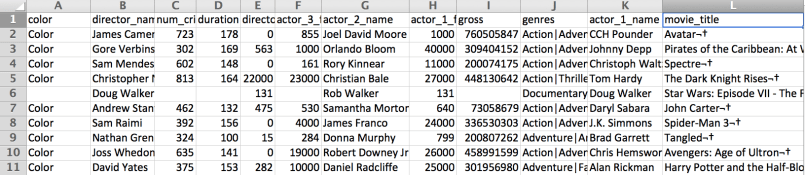
>>> data.movie_title = data["movie_title"].str.upper() >>> data.movie_title = data["movie_title"].str.strip() >>> data.movie_title[:10] 0 AVATAR 1 PIRATES OF THE CARIBBEAN: AT WORLD'S END 2 SPECTRE 3 THE DARK KNIGHT RISES 5 JOHN CARTER 6 SPIDER-MAN 3 7 TANGLED 8 AVENGERS: AGE OF ULTRON 9 HARRY POTTER AND THE HALF-BLOOD PRINCE 10 BATMAN V SUPERMAN: DAWN OF JUSTICE
Una vez terminamos exportamos el resultado a un nuevo archivo .csv pudiendo especificar el tipo de codificación, para el caso UTF-8
data.to_csv("cleanfile.csv", encoding="utf-8")
El resultado final nos da un archivo con el formato deseado y sin faltantes en las columnas de interés.
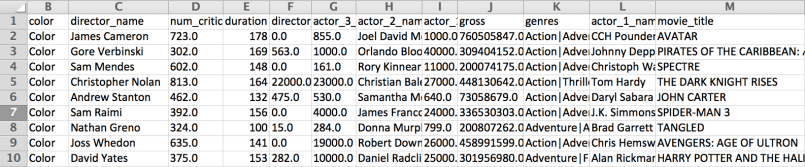
Si tenemos que realizar el mismo proceso con muchos archivos generaremos un script con el proceso de transformación ya probado, de modo que podamos ejecutarlo cuantas veces lo necesitemos.
El siguiente video explica de forma detallada el proceso antes descrito.
