En el último webinar del año de 0 a 100 en Cloud Computing hablamos de las ventajas del uso de Bases de Datos ubicadas en infraestructura en la nube, y nos adentramos en las Bases de datos SQL en Microsoft Azure con un demo de como configurar una base de datos SQL Server y gestión básica.
¿Sabías que el 60% de las compañías que sufren pérdidas importantes de datos tienen riesgo de cerrar en los siguientes 6 meses?* En este webinar hablamos de la importancia de los planes de recuperación y del uso de sistemas de backup en la nube. En esta ocasión exploramos Azure Backup as a service y desarrollamos un demo de backup sobre una máquina virtual completa, incluyendo restauración parcial de archivos y recuperación total de copia.
Continuando con los temas de DevOps, este webinar muestra como realizar despliegue automático de código alojado en un repositorio en GitHub, hacia una WebApp ubicada en la nube de Azure, utilizando como pipeline Azure DevOps. Una vez configurado cada commit sobre el repositorio desencadena un despliegue automático sobre la WebApp.
Visualización de Datos Geo-localizados con Python Folium, sobre Open Street Maps. Puedes consultar el código empleado en GitHub
Este fue el último Webinar del año de Women Who Code Medellín. Para 2019 planeamos volver a los Meetup presenciales en Medellín y realizar algunas actividades en Bogotá. Estén atentas a los eventos en Meetup, pueden seguirnos en Facebook e Instagram.
A continuación un par de video que explican cómo crear Web Apps en la nube de Microsoft Azure, sacando provecho del tier gratuito para la realización de pruebas. Además cómo configurar el despliegue de código hacia la web app desde un repositorio local en Git.
El uso de infraestructura en la nube ha permitido que tareas de administración de TI que antes consumían gran cantidad de tiempo y recursos puedan ser centralizadas y ejecutadas de forma automatizada y sistemática. En este artículo planteamos un recorrido por los últimos 20 años de avances en metodologías y tecnologías de centros de cómputo y como la computación en la nube ha permitido la mejora contante de ellas.
La historia
En mi primer trabajo en un área de sistemas recibí en la primera semana lo que para la época podría ser la “iniciación” al trabajo, el encargado de centro de cómputo me dice: Ahí está el servidor, el CD y el instructivo, cuando regrese debe estar instalado el sistema operativo. Si bien ya había aprendido mi trabajo anterior a ese que muchas cosas pueden sacarse de los manuales, los procesos de entrenamiento y documentación de la infraestructura no eran para entonces muy sistemáticos; al menos en mi caso me dejaron un instructivo claro, pero hubo escenarios donde tenías una caja de CDs, un montón de manuales y Google no existía entonces, debías resolverlo tu mismo con tus manos.
Ese tipo de escenarios también implicaban que cuando el de Sistemas se iba podía dejar el mundo ardiendo, la empresa sin claves de acceso a los datos y la configuración de las aplicaciones en una inmensa caja negra que solo gurús específicos podían abrir. Los inicios del hacking sirvieron para que los encargados de sistemas tuvieran herramientas para recuperar accesos cuando alguien olvidaba, cambiaba por accidente o simplemente se negaba a entregar las contraseñas por algún conflicto de intereses.
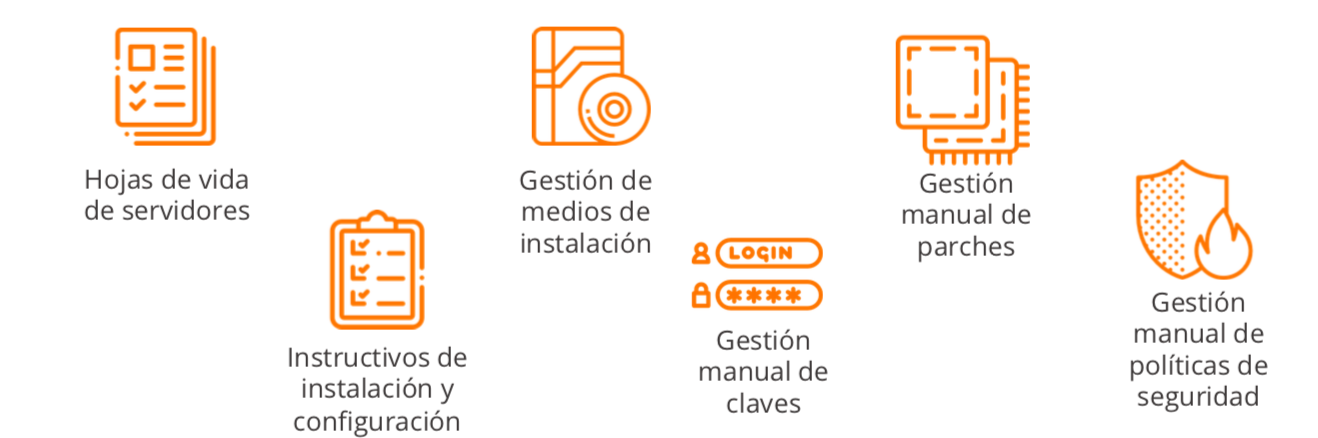
Con el advenimiento de los sistemas de aseguramiento de la calidad, este tipo de metodologías comenzaron a permear el mundo de la computación, así modelos como ITIL comenzaron a ser empleados por grandes empresas que descubrieron la importancia de documentar de manera sistemática las operaciones y cambios que tenían lugar en la infraestructura de TI. Sin embargo fue una solución metodológica que en sus inicios se convirtió en un gran dolor de cabeza, porque si bien los activos eran intangibles, la documentación si que era física, entonces se requería llevar hojas de vida de servidores, repositorios de manuales, bibliotecas de CDs con instaladores y en los escenarios más oscuros cuadernos llenos de contraseñas compartidas entre grupos de administradores. La intención era correcta, las herramientas disponibles aún insuficientes.
Las acciones repetitivas
Tuve un compañero que bien decía que la pereza era la madre de todas las automatizaciones, cualquier cosa que requiriera realizarse más de una vez, él tenía toda la disposición y método para hacer un script que lo solucionara. Claro que también había gente dispuesta a dar click cien veces sobre el mismo botón para cambiarle un parámetro a un grupo de usuarios de un Directorio Activo, pero yo bien estaba de acuerdo con mi amigo que prefería liármelas con un script de ldif en una hora y no cuatro dándole click a la pantalla.
Esos días no eran muy amigables sobre todo para quienes éramos Sysadmin de Wintel (término para aquellos quienes administrábamos plataformas windows sobre procesadores intel) la cantidad de operaciones de la interfaz gráfica que no tenían equivalente en línea de comandos era desalentadora, y las que si tenían equivalente contaban con un nivel de complejidad alto y no tanta documentación disponible. El buscador de Google ya existía pero entonces lo más confiable era irse directamente a la web del fabricante para encontrar documentación precisa y cierta. Los repositorios públicos de scripts y comunidades técnicas con foros en línea era algo que apenas se venía gestando, pero que tomaba rápidamente fuerza gracias a las comunidades de desarrollo Open Source.
Eso en mi máquina funciona
En las compañías más grandes y mejor organizadas las metodologías de desarrollo que propenden por la separación de ambientes comenzaron a hacerse populares, pero con limitaciones importantes por el costo de la infraestructura, teniéndose entonces equipos de las más variopintas arquitecturas en cada uno de los ambientes y haciendo indispensable que varias aplicaciones corrieran en el mismo servidor por optimización de recursos, pero en ocasiones con efectos colaterales indeseados. Esta heterogeneidad de ambientes y configuraciones hacía que en ocasiones al pasar cambios o actualizaciones de aplicaciones de un ambiente a otro, de forma totalmente manual por instalación en cada uno, generaran errores que no se habían presentado en escenarios previos y la consabida frase del desarrollador que tanto detestamos en infraestructura “Eso en mi máquina funciona”, expresión de franco desacuerdo entre dos equipos de trabajo entonces claramente diferenciados y no necesariamente coordinados en sus acciones.
Uno de los asuntos más complejos, sobre todo en las plataformas Windows era la liberación constante de parches de seguridad (al menos el primer martes de cada mes) y que era necesario aplicar uniformemente en todas las plataformas. Los parches de sistema operativo tienen la mala costumbre de romper el software que tienen instalado encima, en los mejores casos porque deshabilitan opciones que el fabricante considera inseguras, en el peor de los casos porque el desarrollador aprovecha configuraciones inseguras para realizar ciertas acciones con el código o por franca ignorancia de los efectos de una cosa sobre la otra. Esto hacía que para las empresas el parcheo de sistemas operativos se convirtiera en una tarea de ensayo y error, pero en ocasiones tratándose de ensayo destructivo.
Automatización en Cloud
Esta gran cantidad de situaciones adversas y la ausencia de herramientas apropiadas son situaciones que comenzaron a ser resueltas por una tecnología que inicialmente no estaba pensada para ello, la virtualización de equipos de cómputo. Estas aplicaciones comenzaron a ofrecer la posibilidad de instalar sistemas operativos completos separados entre sí ubicados dentro de infraestructuras físicas compartidas, con capacidades de procesamiento robustas. De este modo se minimizó la cantidad de hardware físico que era necesario adquirir.
La computación en la nube nació entre otras por la posibilidad de concentrar en un mismo espacio físico gran cantidad de servidores y poder “alquilar” parte de ellos en forma separada para clientes diferentes, la virtualización creó las condiciones para que fuese posible establecer nichos aislados entre sí dentro de la misma máquina física, haciendo económicamente viable el modelo de negocio de alquiler de espacios de cómputo y almacenamiento.
Esta “replicación” de máquinas creó una capacidad que antes no se vislumbraba, la posibilidad de hacer clones de la misma infraestructura, sin tener que luchar con la diversidad de hardware y controladores del mismo que hacían casi imposible en muchos casos estas copias completas en ambientes físicos.
Esta nueva forma de ver la infraestructura, como un aspecto replicable crea el paradigma de la Infraestructura como Código (IaaC por sus siglas en inglés) que propende por tratar la configuración de plataformas y sistemas operativos por medio de scripts repetibles que pueden ser almacenados en repositorios de código y controladas sus versiones, estas capacidades están siendo cada día aprovechadas con mayor énfasis en las infraestructuras de nube, pues facilitan el despliegue, administración y recuperación de desastres, en escenarios donde con solo almacenar el respaldo de los datos y los scripts de configuración de la infraestructura es posible restituir a operación un centro de cómputo completo en cuestión de minutos en una ubicación designada en un país diferente y con la garantía de que se comportará de forma homogénea con el sistema que reemplaza
Qué cosas podemos automatizar:
Capa de Servidor: Utilización de plantillas y perfiles que permiten hacer repetible la configuración de hardware tipo Blade, sistemas operativos y dispositivos activos que los conectan.
Capa de Software: Configuración de aplicaciones en plantillas que pueden ser desplegadas a partir de umbrales de carga y habilitadas por medio de balanceadores de tráfico.
Capa de virtualización: Creación y destrucción de máquinas virtuales a demanda.
Capa de Cloud: Gestión de nubes completas privadas o públicas para procesamiento de cargassegún necesidades variables.
Capa de Datacenter: Tecnología en desarrollo. Uso de automatismos robóticos para ejecutar las tareas físicas de monitoreo y reemplazo de equipos que actualmente realizan seres humanos.
Esta nueva forma de ver la infraestructura automatizada creó una nueva disciplina: DevOps, donde se unen las responsabilidades del desarrollo de software con las de despliegue de las plataformas base, en pocas palabras propende por:
Unificar las tareas realizadas por los equipos de Desarrollo y Administración de Sistemas.
Mejorar la comunicación entre Desarrollo y Operación dado que cada vez más elementos de la infraestructura se vuelven programables.
Integrar la cadena de entrega de software como un todo, supervisando los servicios compartidos y aplicando mejores prácticas de desarrollo. Eg: Agilismo.
Liberar nuevas funcionalidades en las aplicaciones con mayor frecuencia.
Usar de herramientas de control de código fuente, que también pueden almacenar la configuración como código.
Los datacenters continuarán avanzando y las operaciones que se realizan en ellos serán cada día más automatizadas, los paradigmas de gestión de los recursos de TI han encontrado en la infraestructura en la nube el aliado adecuado para hacer cada día más sencillo y amplio el acceso a recursos de cómputo, para beneficio de las empresas de todo tamaño y quienes administran tales sistemas.
Como usar la librería Scikit-Learn para entrenamiento de modelos y prueba de los mismos. Código basado en Python Data Science Handbook con algunas correcciones.
Código disponible en el repositorio de GitHub de WWCode Medellín.
El ser humano es lúdico por naturaleza, jugamos desde la cuna y ya de adultos el juego sigue facilitando procesos de aprendizaje y comunicación. Los juegos electrónicos han recorrido un largo camino desde el inicio de la computación hasta las modernas plataformas que utilizan infraestructura en la nube para ser operados y a los cuales tienen acceso miles de jugadores simultáneos.
El primer juego en una computadora surgió en 1952 con un simple “Tres en línea” en el cual se podía competir contra un computador, posteriormente aparecieron los primeros juegos con interacción humana por medio de controles simples que modificaban la reacción de un osciloscopio, creando un juego que simulaba el ir y venir de una pelota de tenis. Los juegos fueron haciéndose más complejos y durante los años 70 se hicieron populares las máquinas de videojuegos, instaladas en centros comerciales y negocios dedicados solo al juego, debido a que en aquel entonces no existía hardware destinado a este fin en los hogares. Con el advenimiento del computador personal se popularizaron los juegos que utilizaban la pantalla del televisor como interfaz visual, conectados a un computador encargado del procesamiento; estos juegos fueron evolucionando una vez la interfaz gráfica se hizo más potente y la capacidad de procesamiento de los computadores permitió llegar hasta generar escenarios en 3D.
Simultáneamente los fabricantes de videojuegos se encargaron de crear hardware dedicado para jugar, con gran capacidad de procesamiento gráfico y controles para interacción del usuario con reacciones cada vez más realistas. Sin embargo esto limitó a los jugadores a depender del hardware específico y de la renovación constante de este para contar con las últimas versiones del videojuego.
La aparición de los escenarios multi-jugador por la red permitieron encontrar con quien jugar básicamente a cualquier hora del día, conectando participantes en todo el mundo a través de avatares. La conexión a internet juega un papel muy importante cuando se trata de juegos que requieren rápida reacción, y que están sujetos al “Lag” término usado para denominar el retardo en tiempo entre una acción del jugador y el reflejo de tal acción dentro del juego, que puede deberse a múltiples motivos como una saturación en el procesamiento de video local o una fluctuación en la velocidad del canal de Internet. El lag es por mucho una de las experiencias más frustrantes para los jugadores.
En estos entornos resulta crucial tener acceso no solo a canales rápidos sino también que los servidores donde se alojen los sistemas de juego estén lo más cerca geográficamente posible de sus destinatarios, de modo que el retardo introducido por la distancia no malogre el desempeño del jugador.
La más reciente tendencia en videojuegos se aleja de la necesidad de consolas y plantea el acceso a los videojuegos en la modalidad de Streaming, así como un Netflix donde se paga una suscripción por tener acceso a jugar un gran menú de juegos, de modo que no es necesario invertir una consola nueva para mejorar sino que el procesamiento se realiza centralizado, una plataforma que ya ofrece este modelo es Gloud. Existen indicios de que Google se encuentra desarrollando un proyecto interno para ofrecer una plataforma en la nube de gran tamaño para procesamiento de juegos y permitiendo a personas con hardware modesto poder acceder a experiencias de gráficos e interacción de última generación, venciendo la barrera del hardware. Una plataforma de estas características ya ha sido desarrollada por NVIDIA como GE Force Now donde el fabricante de procesamiento de video permite acceder hasta el momento en modelo de Beta (prueba) a juegos totalmente en línea. AWS también ha entrado con su potente nube, distribuida geográficamente de tal modo que facilita el acceso de cualquier jugador en cualquier lugar del mundo; con su propio engine de procesamiento de juegos
Los desarrolladores de videojuegos tienen en frente un cambio de paradigma en la forma como su contenido se distribuye, pasando de depender del hardware para el cual desarrollan a nuevos modelos de streaming donde deberán competir igualmente para atraer jugadores, pero con la ventaja de acceder a públicos más amplios no restringidos por la infraestructura. Los entornos en la nube facilitan también el procesamiento en la creación de videojuegos, como es el caso de los servicios de renderizado en la nube de Google Zync, donde se cuenta con grupos desde 50 máquinas para tareas de renderizado y se paga solo durante el tiempo de ejecución de la tarea, reduciendo la demanda en compra de hardware y maximizando la capacidad para cumplir con flujos de trabajo exigentes.
La nube llegó para quedarse en muchas de las industrias que conocemos, los videojuegos son una de ellas, veremos en el futuro cercano como ayudará a la mejora de las experiencias de los usuarios y de la mano del hardware de sensores evolucionarán hasta integrarse con la realidad virtual.
Compartimos el webinar realizado en el grupo de Meetup De 0 a 100 en cloud computing, donde tratamos el tema de SaaS (Software as a Service) en este caso las plataformas en la nube que permiten a las empresas hacer más eficientes las reuniones de sus equipos de trabajo y facilitar la interacción remota con empleados, proveedores y clientes. Detallamos los servicios que ofrece Microsoft bajo la sombrilla de Office 365, los cuales más allá de la ofimática brindan herramientas de redes sociales corporativas, intranet, teleconferencia, chat, seguimiento de proyectos, entre otros. Al final se realiza un demo en línea sobre la herramienta Microsoft Teams y su uso en dispositivos móviles.





 La más reciente tendencia en videojuegos se aleja de la necesidad de consolas y plantea el acceso a los videojuegos en la modalidad de Streaming, así como un Netflix donde se paga una suscripción por tener acceso a jugar un gran menú de juegos, de modo que no es necesario invertir una consola nueva para mejorar sino que el procesamiento se realiza centralizado, una plataforma que ya ofrece este modelo es
La más reciente tendencia en videojuegos se aleja de la necesidad de consolas y plantea el acceso a los videojuegos en la modalidad de Streaming, así como un Netflix donde se paga una suscripción por tener acceso a jugar un gran menú de juegos, de modo que no es necesario invertir una consola nueva para mejorar sino que el procesamiento se realiza centralizado, una plataforma que ya ofrece este modelo es 
