

Por: Isabel Yepes
En esta publicación mostramos como hacer un análisis de palabras simple denominado WordCloud, que muestra una imagen con las palabras más frecuentes en un texto, dándoles relevancia por tamaño. Usaremos como fuente textual los tweets de una determinada cuenta, que han sido previamente descargados en csv.
El código aquí presentado se basa en el artículo de DataSciencePlus Twitter Analysis with Python
Para comenzar debemos instalar las librerías pre-requisitos
$pip3 install pandas $pip3 install numpy $pip3 install Matplotlib $pip3 install WordCloud $pip3 install NLTK
Una vez instalado nltk debemos descargar los diccionarios de palabras que necesitamos, para este caso las stopwords, que son las palabras conectoras que repetimos con frecuencia en un idioma, por ejemplo pronombres como el, la, los, e.o.
En el caso de OSX la descarga requiere que la fuente tenga un certificado instalado, por lo cual debemos cumplir este requisito antes de hacer la descarga, ingresando a la ruta de la aplicación e instalando el certificado
$cd /Applications/Python\ 3.7/ $sudo install ./Install\ Certificates.command
Realizar la descarga
$python3 >>>import nltk >>>nltk.download
Seleccionar del corpora de nltk las stopwords

Debemos contar ya con un archivo con información de twitter descargada, puedes tomar como referencia las instrucciones de Como descargar tweets a .csv usando Python teniendo en cuenta que la forma de crear credenciales de descarga para twitter cambió y ahora debes aplicar por una cuenta de desarrollador antes de crear la aplicación. El video al final de este post habla un poco de ello. En este enlace de Twitter Developer puedes comenzar ese proceso.
El siguiente script contempla que tienes dos archivos, uno con los 400 últimos tweets llamado sample_tweets-400.csv y otro con los últimos 3240 llamado sample_tweets.csv. Este script también puede encontrarse en el siguiente repositorio, con el nombre wordcloud.py https://github.com/WomenWhoCode/WWCodeMedellin
import numpy as np
import pandas as pd
import re
#Visualización
import matplotlib.pyplot as plt
import matplotlib
from wordcloud import WordCloud, STOPWORDS
#nltk librería de análisis de lenguaje
import nltk
#Este proceso puede hacerse antes de forma manual, descargar las stopwords de la librería nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stop_words_sp = set(stopwords.words('spanish'))
stop_words_en = set(stopwords.words('english'))
#Concatenar las stopwords aplicándose a una cuenta que genera contenido en inglés y español
stop_words = stop_words_sp | stop_words_en
from nltk import tokenize
matplotlib.style.use('ggplot')
pd.options.mode.chained_assignment = None
#Últimos 400 tweets previamente descargados
tweets = pd.read_csv('sample_tweets-400.csv')
#Últimos 3240 tweets previamente descargados
tweets2 = pd.read_csv('sample_tweets.csv')
def wordcloud(tweets,col,idgraf):
#Crear la imagen con las palabras más frecuentes
wordcloud = WordCloud(background_color="white",stopwords=stop_words,random_state = 2016).generate(" ".join([i for i in tweets[col]]))
#Preparar la figura
plt.figure(num=idgraf, figsize=(20,10), facecolor='k')
plt.imshow(wordcloud)
plt.axis("off")
plt.title("Good Morning Datascience+")
def tweetprocess(tweets,idgraf):
#Monitorear que ha ingresado a procesar el gráfico
print(idgraf)
#Imprimir un tweet que sepamos contenga RT @, handles y puntuación para ver su eliminación
print(tweets['text'][3])
tweets['tweetos'] = ''
#add tweetos first part
for i in range(len(tweets['text'])):
try:
tweets['tweetos'][i] = tweets['text'].str.split(' ')[i][0]
except AttributeError:
tweets['tweetos'][i] = 'other'
#Prepocesar tweets con 'RT @'
for i in range(len(tweets['text'])):
if tweets['tweetos'].str.contains('@')[i] == False:
tweets['tweetos'][i] = 'other'
# Remover URLs, RTs, y twitter handles
for i in range(len(tweets['text'])):
tweets['text'][i] = " ".join([word for word in tweets['text'][i].split()
if 'http' not in word and '@' not in word and '<' not in word and 'RT' not in word])
#Monitorear que se removieron las menciones y URLs
print("------Después de remover menciones y URLs --------")
print(tweets['text'][3])
#Remover puntuación, se agregan símbolos del español
tweets['text'] = tweets['text'].apply(lambda x: re.sub('[¡!@#$:).;,¿?&]', '', x.lower()))
tweets['text'] = tweets['text'].apply(lambda x: re.sub(' ', ' ', x))
#Monitorear que se removió la puntuación y queda en minúsculas
print("------Después de remover signos de puntuación y pasar a minúsculas--------")
print(tweets['text'][3])
#hacer el análisis de WordCloud
wordcloud(tweets,'text',idgraf)
#Graficar tendencia 400 tweets
tweetprocess(tweets,100)
#Graficar tendencia 3240 tweets
tweetprocess(tweets2,200)
plt.show()
La salida generada son dos imágenes que muestran la tendencia de los últimos 400 tweets y los últimos 3240

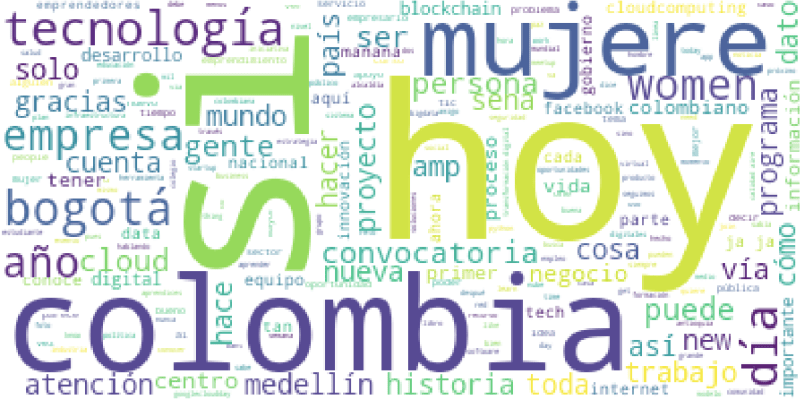
Aquí la explicación en video del código empleado
